ML - Cookie Cutter

Love working on Quantum Physics , C, Swift and Rust
Introduction
My first blog was on the beginner's guide to DS and ML and how to structure your files and folders while running experiments on Jupyter notebook. In this article, I will talk about the next phase i.e. structuring your entire ML project in production.
ML in Production
Once your model is ready, you need to create a folder structure to manage your source code, data, charts, hyper parameters, models, reports etc.
Wouldn't it be nice to have a custom script which gives you this skeleton - A cookie cutter, maybe?
Well, there is one called DS Cookie cutter. This is absolutely brilliant, but wanted a simple one that I could manage for better control.
Cookie-ML Project
There are two ways to use this script
1 - Using make & Makefile
2 - Run .py script directly
Flexibility is the key!
Approach One - Using make & Makefile
If you have not heard about make utility, it's very popular for automating the compilation of C/C++ programs and their dependencies. It is already installed on Linux & Mac OS.
Prerequisites
The prerequisites is to have a virtual environment created. There are three ways of doing this:
conda- easier and works well but only during experimental phase of your projectvirtualenv- was popular once and works well with pippipenv- is the most preferred method as it combines pip & virtualenv
Once you activate the virtual environment, just run the following command and it will create a folder structure - ml-project
make build
To install ML libraries, update the requirements.txt and run
make install_libraries
If you want to see more options use :
make
Approach Two - python script
If you want to keep it simple just use the command below and it will create the structure outside the current directory you are in.
Prerequisites
The only prerequisites is to have python 3.x installed.
Optionally - If you have the virtual env created, you can activate it and then run :
python template.py folder-name
folder-name is the required parameter, just make sure you do not have another folder with the same name. It is that simple!!
Folder Structure
This section provides a quick reference on the structure.
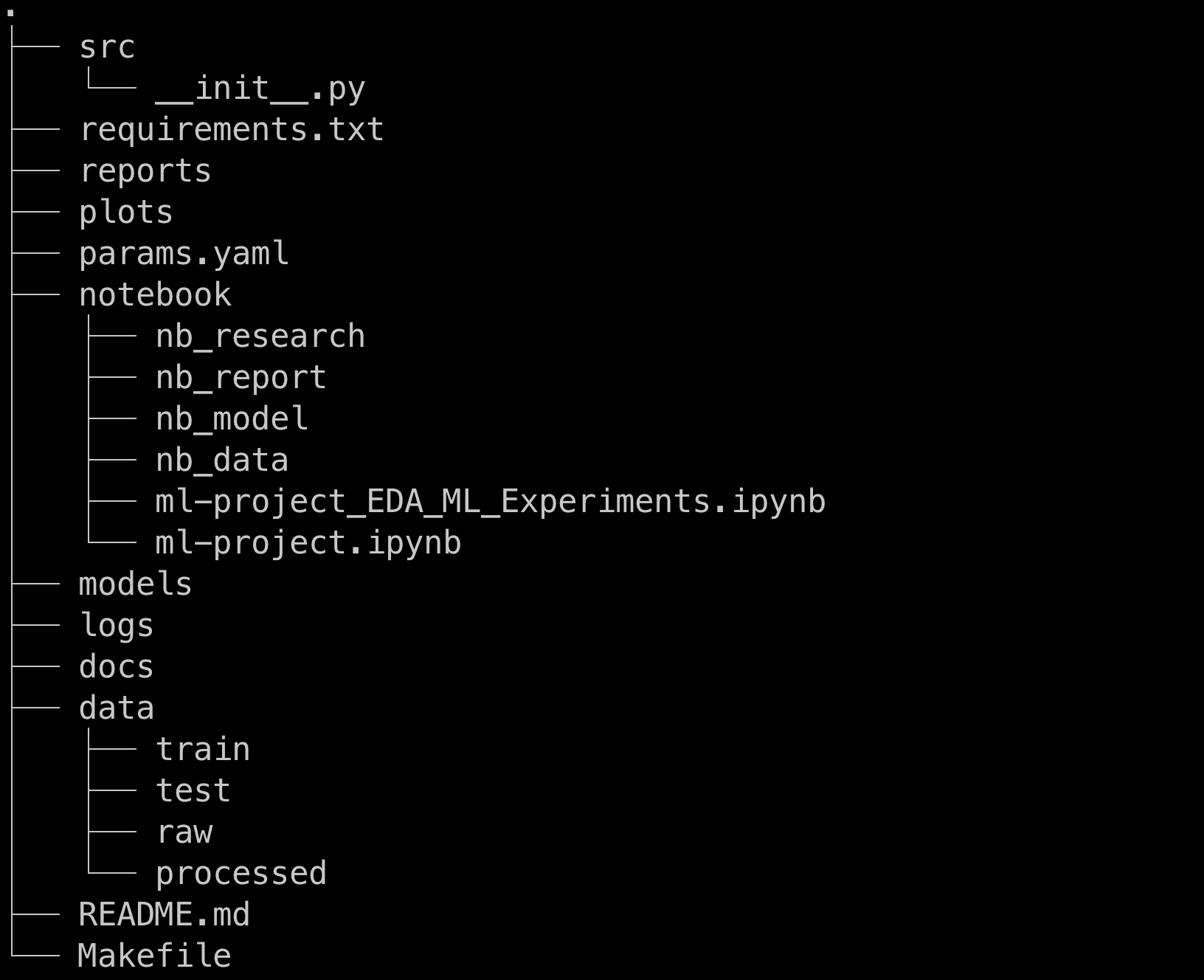
Structure details
src - Most of your code lives in this folder e.g. main.py, preprocess.py, visualizer.py etc.
requirements.txt - If you use conda or virtualenv to install ML libraries then update this file but if you prefer pipenv then replace it with Pipfile. Will be supporting this in the next release.
reports - All reports are stored here after data processing/cleaning. Store reports (xlsx, csv format) to be sent at regular intervals.
plots - Storing graphs(png/jpg). This can be used for presentation/publishing papers or used in project documentation.
params.yaml - YAML file for storing data, model configurations.
notebook - Stores all your jupyter notebooks which is used during your experiment/research phase . The sub folders are :-
nb_research - to store all your artifacts, notes, reference links.
nb_report - Storing all your sample reports.
nb_model - For storing your params, model during your experiment phase.
nb_data - folder contains all the data used during your research.
project_name_EDA_ML_Experiments.ipynb - filename is same as project name.
project_name.ipynb - Final clean code lives here.
models - to store all the models you would have trained with lots of hyper params.
logs - stores the logs, to be consumed by tools e.g Promethus/Grafana.
docs - for building documentation - all your artifacts can be used for creating documentation.
You can use MKDocs or any static website generator. If you know React JS - try Docusaurus.
data - to store data. Following are the sub folders:
train - For training you model
testing - For storing unseen data
raw - original data
processed - cleaned/transformed data which will be split into train or test data
Readme.md - Landing page of your project which is a markdown file.Makefile - To automate your script and it's dependencies.
Complete code is available here at Github.
Future Support
- Virtual environment
- DVC (Data Version Control)
- Docker
- MKDocs & Docusaurus
Conclusion
Stephen Hawking once said :
One of the basic rules of the universe is that nothing is perfect.
So is my script, but it has worked well for me and it gets the job done!
If you have any questions or feedback - do reach out to me on Twitter or Linkedln
Happy Learning!!




